
[This blog was originally published on November 19, 2019 and was updated on January 05, 2021.]
Staging Environments are a challenge not only because they simulate and aim to replicate production, but because they also serve different teams with varying use cases and requirements. In today’s world where DevOps processes and public clouds (AWS, Azure, etc.) have a big role and provide innovative solutions, it’s worth taking a fresh approach to how we redefine and rethink our development process.
There are many sub-steps in the DevOps process that complicate making the big leaps needed to construct a reliable application release pipeline. Staging environments are used as potentially temporary environments that match production, ensuring that productions are well-tested. But even today, DevOps teams find it very hard to create development environments and test environments that simulate production, and in many cases this obstacle causes the entire CI/CD pipeline to break.
In this article, we will describe common patterns for creating staging environments and offer some best practices that will help you minimize the risks.
Redefining the Development Process with Staging Environments
What Is an Environment?
Environments are made from multiple components. Today, you can have VMs, load balancers, cloud services, or databases in your environment. Tomorrow, your application may encompass a whole different arrangement of applications, infrastructure, data, integrations, and monitoring systems.
When we talk about staging environments, there are several use cases that stretch across different organization stakeholders. The Engineering Team use case includes last-mile validation on a production-like environment and testing third-party integrations. The Product Team commonly employs a staging environment to review the product for bugs and identify potential errors in the running application. The DevOps Team requires the staging environment to test the production upgrade process and make sure the Monitoring, Alerting, and other testing systems run smoothly. And let’s not forget the Biz Dev and/or Sales Teams that require environments to run company demos and PoCs (Proof of Concept).
3 Common Patterns for Creating Staging Environments
Static Staging Environments
The traditional “static” staging reality of application development is “bumpy” with many back-loops. Engineers may often restart services while development teams suffer from corrupted databases and thus troubleshooting ensues. This is expected, but it certainly isn’t linear.
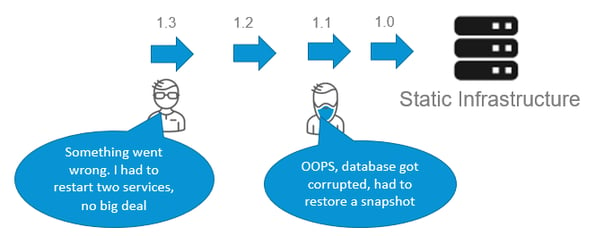
Unfortunately, static staging environments are difficult to scale when many teams are simultaneously working on the same static infrastructure. But if static is what works best for your application, then follow some of the strategies below:
- When starting every sprint, recreate the environment
- Occasionally refresh the data
- Rely on “cleaned-up” production data
- Apply monitoring and alerting processes that closely match production
Assign owners and clearly define their responsibilities. If static staging environments limit your teams’ development, what are some alternatives?
On-demand Staging Environments
Here we find ourselves in the world of dynamic infrastructure options that are offered by cloud providers such as AWS, Azure, or Google Cloud. With dynamic infrastructure automation and on-demand staging we’re able to provide each of our development teams their own resources that they can manage as needed; the result of which is no bottlenecks and decreased work frustration.
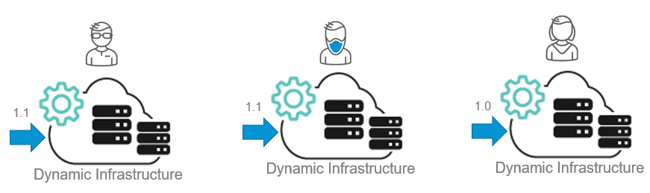
Dynamic staging/self-service environments allow each team to evaluate and regulate their environment as a product. Now they can determine:
- When specific environments will start and end (affects cost implications)
- Who has access to the environment and can edit or view it
Of course, nothing is ever perfect for every situation. Dynamic staging is challenging because governance and use policies must be determined per team, which can be complicated. Security issues and the integration of multiple cloud providers and teams can further complicate processes. But the best things about working with dynamic staging are that developers are closer to production, environments become scalable and easier to consume, there are minimal work interruptions for each team, and environments become automated and properly managed, thus providing the oil for a smooth-running machine.
The “Live” Staging Model
For those of you who want to practice continuous delivery and release new versions to production without manual gates, we recommend investing in the live staging model. The production is upgraded with the popular blue/green strategy, and there’s no need for standalone staging. This means continuous and automatic deployment is in the users’ hands.
Risk management and staging phases co-exist as new versions are constantly developed, tested, and put into production. A big part of the live staging model is the concept of canary releases and blue/green deployment. Quali CloudShell Colony provides both.
Blue/green deployment involves running two versions running simultaneously in production. Before upgrading the production to a newer version, we can test, monitor, and debug on the real (live) production.
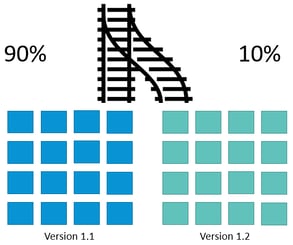
Using blue/green deployment via the CI/CD tool, teams can choose to deploy to production, get feedback, update and fix, and then redeploy the new parts while the stable sections have been maintained for the application users. This reduces risk and enables continuous usage.
When using blue/green deployment, teams must design for backwards/forwards compatibility, be very careful with state and using different versioning patterns, emphasize specific testing characteristics of dynamic version changes, and create backlog planning for the entire blue/green cycle.
Although there’s added complexity, the added benefits clearly show blue/green’s superpowers. Risks are mitigated since changes are rolled out slowly and corrected continuously during each iteration. Testing and monitoring of the production process is ongoing like a system of checks and balances. Releases are completed more quickly, and feedback is available faster. All these small iterations and packaged changes allow business to run smoothly with significantly reduced downtime.
Exciting stuff, right? We’ve got a lot more up our sleeves and the experienced practice for some good discussion! Tune in next month for the nitty gritty of CI/CD practical tips and best practices.
Download our “Buyer’s Guide To Scaling DevOps” to learn more about what it takes to scale DevOps using an Infrastructure Automation tool.


