
For the typical DevOps engineer, Infrastructure as Code has become the de facto standard, providing significant control and velocity over the entire application release process. While there is no questioning the benefits this approach has brought to automation of the datacenter, with new powers come new responsibilities.
In this new paradigm, the separation of duty between Application development teams and IT is no longer relevant. If this is the case, how do automation engineers manage the application infrastructure?
As Infrastructure as Code gains some maturity, DevOps managers moving from experimentation to full scale production, have come to realize it takes a different type of solution to apply Infrastructure as Code practices to their entire organization. Just like breadmaking, where the techniques used for baking a loaf at home may not be effective when running a bakery business.
Ansible Inventory Files: the Traditional Approach
[caption id="attachment_14672" align="alignnone" width="534"]

Example of an Ansible Inventory file[/caption]
I will attempt to answer that question using Ansible has an example. Turns out CloudShell has a tight integration with Ansible. since Ansible is tightly integrated with CloudShell, this is certainly not a random pick and the value of the combined solution is significant for the application release manager.
Let's consider the typical process to deploy Applications using Ansible. Note that this approach will be fairly typical with other frameworks like Terraform, Chef or Puppet.
For a very simple deployment, the process goes as follow:
- Create an inventory file with a list of target servers
- Apply a playbook (script) to that inventory file. The Ansible open source community offers a large library of playbooks that shortens the scripting effort significantly.
These files may be managed through a Git repository for source control, or a commercial offering such as Ansible Tower that may also provide the capability to run the playbook (instead of the vanilla Ansible service).
While this might work for a single website, it will create significant challenges over time to make it work at scale for more complex applications.
The most simple approach is to create an inventory file with a static group of servers. However, over time the production environment will evolve and change independently (for instance the type of server used). This will have to be reflected in the server inventory file to make sure the test environment is in sync with the production environment. Short of maintaining a tight synchronization, the test environment will eventually diverge from the actual production state and bugs will remain undetected until late in the release cycle.
The alternative is to include dynamic parameters in the Ansible inventory file and manage these parameter values with some custom built solution on top of Ansible, which eventually has to be managed as a custom set of scripts. that means relying on some in-house processes or code that needs to be maintained. This can become notoriously difficult to troubleshoot, especially when it comes to complex applications.
Finally, compounding these two challenges, a large enterprise may want to implement a for one or more application portfolio. that means an external process to scale is required, as well as proper governance to make sure infrastructure put in place is not under-utilized.
Using CloudShell Orchestration to Create Dynamic Inventory Files
[caption id="attachment_14673" align="alignnone" width="1000"]
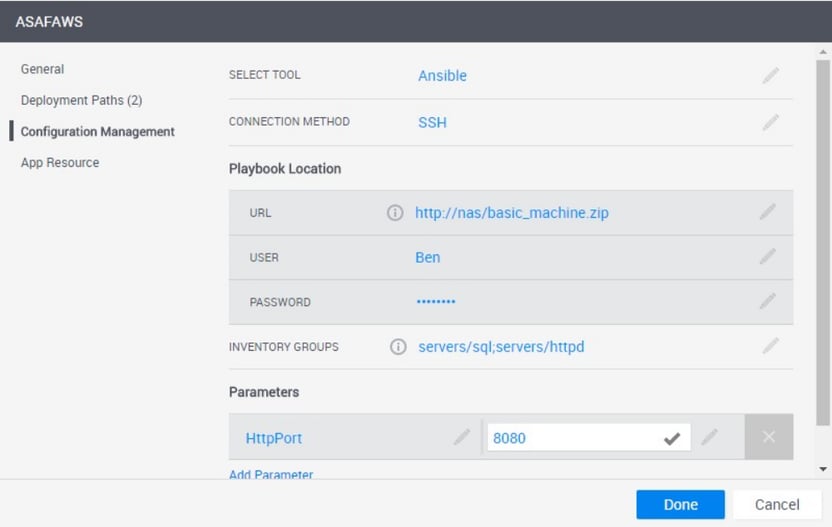
CloudShell App Template Configuration Management with Ansible.[/caption]
Let's now take a look at how these concerns can be addressed using the CloudShell Platform:
Step 1: Define an application template (also called "App Template"). These application templates constitute standard reusable building blocks and provide the foundation for a large number of blueprints. If we use the breadmaking analogy, this would be the "leaven". Cloudshell natively supports Ansible, so that means users can model Application templates and directly point to an existing playbook repository. That also means users can directly benefit from a rich set of application templates available from the open source Ansible Galaxy community. The Administrator can also define several infrastructure deployment paths that will correspond to different cloud providers.
Step 2: Create a blueprint to model complex application. Using CloudShell visual diagraming, this is a simple process that involves drag and drop of the previously defined application template components onto a web canvas. each blueprint may have one or more dynamic parameter as relevant, such as the application build number or the dataset.
Step 3: Publish blueprint to the self-service catalog. This self-service catalog organizes collections of application blueprints relevant to groups of end users (developers/testers) as well as API based external ARA frameworks such as JetBrains TeamCity. This is really the way to scale the process to a large number of applications across an entire organization.
Step 4: Blueprint orchestration: deploy and teardown. This process is triggered by the end user, typically an application tester or an API, who will select a blueprint from a catalog, its input parameters if relevant, and deploy it. The sandbox deployment invokes built-in orchestration to create and configure all the components, VMs, network segments. In the last phase of this automated setup, applications are installed and configured based on the app template definition. That means Ansible inventory files are dynamically created and the infrastructure is deployed on the target cloud environment, as defined in the blueprint. Ansible playbooks are then executed on the target virtual machines. Once the application is deployed, the test process can run either manually or automatically triggered by the ARA tools if in place as part of a predefined pipeline workflow. Finally, the sandbox is automatically terminated so that the application infrastructure is only used for the test duration it is intended for.
In Summary, Combining the power of CloudShell dynamic environments and Ansible playbooks provides a scalable way to certify complex applications without the hassle of managing static infrastructure inventories.
Want to learn more? schedule a demo, download our SDK and try running some real examples from our on line developer guide. Happy baking!

